Программа для распознавания текста.
| deft666 |
|
|
Темы:
54
Сообщения:
167
Участник с: 21 августа 2015
|
Добрый день всем. Подскажите, нужно срочно отсканировать и распознать отсканированный текст с переводом в pdf. Какую программу поставить для распознавания текста? |
| eim6wei9 |
|
|
Темы:
12
Сообщения:
21
Участник с: 16 ноября 2022
|
gimagereader-gtk |
| deft666 |
|
|
Темы:
54
Сообщения:
167
Участник с: 21 августа 2015
|
eim6wei9а как словари установить? |
| cucullus |
|

Темы:
266
Сообщения:
3537
Участник с: 06 июня 2007
|
ох нифига себе как всё продвинулось! работает даже!
такие дела.
|
| konstantinov-ms |
|
|
Темы:
16
Сообщения:
708
Участник с: 29 ноября 2009
|
cucullus…или делает вид, что работает! На англоязычных текстах ещё куда ни шло. На русскоязычных текстах программа минут 10 распознавала ИЗНАЧАЛЬНО ЭЛЕКТРОННЫЙ PDF, а потом не смогла его сохранить. Если распознавать сканы (очень приличного качества), вылезают абсолютно дичайшие ошибки. Ну, и опять же, html программа сохраняет, а на pdf и odt падает. Проверено и на .gtk-, и на qt-версии. Разбираться в причинах было лень. Поскольку как показывает практика, даже если ты сейчас решишь эту проблему, позже вылезет какая-нибудь другая. Не везёт Linux'у с OCR. Пока только Wine. За это же время FineReader 12 в Wine корректно распознал всю книгу под 400 страниц, отправил в .docx-формат, и качество распознавания выше на порядок. С таким качеством распознавания tesseract как шёл лесом, так и продолжает идти. Потому что если нужно по-быренькому распознать один документ, то легко можно воспользоваться онлайн-распознавалками. Если же прибегать к ocr приходится хотя бы несколько раз в месяц, никакой альтернативы FineReader до сих пор нет. Потому что потом ручками разгребать все косяки tesseract получается себе дороже по времени. Двенадцатая версия FineReader прекрасно работает в Wine. Cuneiform давненько не тыкал палочкой, но навряд ли там что-то изменилось, учитывая, что движок замёрз ещё в "нулевых". |
| grayich |
|
|
Темы:
230
Сообщения:
2204
Участник с: 08 января 2009
|
яндекс\гугл переводчики, перевести документ |
| cucullus |
|
|
Темы:
266
Сообщения:
3537
Участник с: 06 июня 2007
|
konstantinov-ms, Вы уверены, что установили tesseract-data-rus? У меня идеально распознало. Печатный сканированный текст, даже с подписями и печатями. Страница секунды за 3-4. Проблемы потом при сохранении, почему-то слова склеиваются, хотя при распознавании всё отдельно. Думаю, это решаемо как-то. В pdf сохранила.
такие дела.
|
| konstantinov-ms |
|
|
Темы:
16
Сообщения:
708
Участник с: 29 ноября 2009
|
cucullusКонечно установил, без этого программа вообще не работала бы: cucullusНе знаю. Возможно, дело в том, что я выбираю сразу три языка распознавания, а не один. Но в FineReader'e я выбирал и больше (включая греческий и латынь, которыми изобилуют научные тексты). и всё работает очень быстро. cucullusПонял, в чём дело. Возможно, у нас с Вами разные представления о качестве распознавания. По моему мнению, как минимум с 2004-го (ну, ладно, с 2008-го) года если программа OCR выдаёт вот такой результат, то это ненормально: "Я сам нейробиолог И в свое время лично ощутил этот па-скалевский ужас. Ощущал я и связанное с НИМ смуще-ние. иногда мне приходится публич-но выступать, расскdзывая о положении дел в нашей сфере науки после одного ИЗ таких выступлений…" Вот реально: это уровень FineReader'а "нулевых" годов. Конечно, тогда мы как-то распознавали тексты, потом вычитывали их, правили ошибки и считали это всё нормальным. Но в 2022 году заниматься этим я не буду. Я поставлю себе FineReadere в Wine и получу приемлемый на 2022 год результат. cucullusУ меня падала. Может быть, потому, что poppler обновился перед этим. Так бывает. Но в .odt тоже не сохраняла, падала. В принципе, я могу потратить время, разобраться, в чём проблема и решить её. И лет десять назад я бы так и поступил. Но сейчас мне жаль тратить время на это. Либо программа работает и удовлетворяет мои потребности, либо я её удаляю. UPD. Кстати, как вариант, проблема может быть ещё и в том, что при распознавании я выбираю не "Простой текст" (в котором убивается всё форматирование), а "hOCR, PDF". Тогда предварительный результат программа сохраняет не в .txt-формате, а в формате .html. А если пытаешься сохранить в .pdf/.odt, падает. |
| cucullus |
|
|
Темы:
266
Сообщения:
3537
Участник с: 06 июня 2007
|
konstantinov-msНу не знаю... Единственно, текст без переносов, т.к. не книга, а документ. В режиме "hOCR, PDF", русский язык. Склеивает слова именно при экспорте. Распознавание идеальное, это меня и потрясло, я не ожидал, по старой памяти. Глючит оболочка. Для целей внедрения текстового слоя в скан вполне годно, только надо экспорт починить. P.S. Подключил английский, запустил двуязычное распознавание. Стало медленнее, страница секунд 20-25. Результат всё равно потрясает. Текст: список литературы, языки вперемешку, много знаков препенания, цифр. Ошибок почти нет! С русско-английскими словами через тире не справился, но это не удивительно. Из забавного: "and" посреди английского текста распознал как "апа" ;) P.P.S. А вот когда исходник криво сфоткан на телефон, тогда всё хуже, конечно. Если строка идёт по дуге, то как повезёт.
такие дела.
|
| konstantinov-ms |
|
|
Темы:
16
Сообщения:
708
Участник с: 29 ноября 2009
|
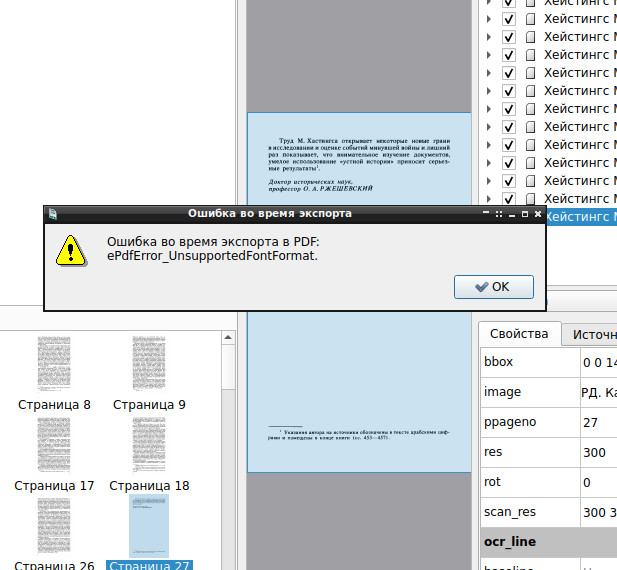
cucullusНе знаю. Документ не пробовал. Взял первую же книгу из библиотеки под 400 страниц. Из них выбрал 40 страниц на распознавание. Распознаёт. Но при передаче в pdf/odt падает. Ну, хорошо, на досуге попробую что-нибудь 10-страничное распознать. Хотя не очень понимаю, зачем держать программу, которая корректно распознаёт только 10 страниц. cucullusЕсли бы не падало. Хотя и для этого держать программу не очень рационально. Онлайн-сервисов множество. Закинули на сервер, через 5 минут скачали результат. В 2022 г. OCR-софт не должен ограничиваться внедрением текстового слоя в документ pdf. С этим уже даже pdf-reader'ы справляются. Но тут, понятное дело, спорить не о чем, ибо вкусовщина: Вас устраивает, а меня нет. cucullusА теперь подключите третий язык :))) А ведь бывают работы, где и по 6 языков используется. cucullus cucullus cucullusСобственно, об этом я и говорил выше: это уровень FineReader'а "нулевых" годов. Никто ж не спорит с тем, что по сравнению с самим собой tesseract продвинулся за последние годы. Просто конкуренты за это время настолько ушли вперёд, что рассматривать tesseract как альтернативу просто не имеет смысла. Лет 10 назад, когда FineReader толком не работал в Wine, иметь под рукой простенькую распознавалку для "по-быренькому получить текстовый слой" в Linux'е, чтобы не искать Windows, имело смысл. Сейчас я этого смысла не вижу. P.S. Таки не поленился и попробовал распознать что-то простенькое. Взял книгу со сплошным текстом (прошлые эксперименты были с картинками, схемами, сложным форматированием и т.д.). Книга историческая (Хейстинг М. Операция "Оверлорд". Как был открыт второй фронт), скан очень хорошего качества (500-страничный pdf "весит" более 25 Мб). Для распознавания на этот раз выбрал не 40 страниц, а только 20. И о, чудо! 20 страниц программа экскпортировала. Правда, накосячила с расширением (файл .odt оказался с расширением .pdf, но это мы и ручками подправить можем!). Смотрим на результаты: https://imagizer.imageshack.com/v2/xq90/923/v6nyDD.png Считаем количество ошибок на страницу (я их выделил красным). Разочаровываемся. Считаем количество ошибок на следующей странице: https://imagizer.imageshack.com/v2/xq90/924/pYUjA6.png Разочаровываемся ещё сильнее. На странице уже левые символы стали появляться "©". Хотя предлоги из заглавных букв на этом тексте отсутствуют. Видимо, скан слишком хороший. Был бы чуть похуже, было бы интереснее. Но окончательно всё сыпется, когда смотрим результат экспорта: https://imagizer.imageshack.com/v2/xq90/922/7DJKgN.png Всё. На этом можно ставить точку. Текст передаётся блоками! Это настолько мозговыносное дело при редактировании, что такой текст проще перенабрать руками, чем отсканировать, а потом что-то подправить. В FineReader это настраиваемая функция. Здесь либо получаешь вообще текст без форматирования, либо с какими-то остатками от убитого форматирования (что мешало, например, сохранить выравнивание по ширине?!), но нередактируемый. Переносить текст из блока в блок - то ещё развлечение! И это при распознавании по 20 страниц! По 40 уже не тянет! Экспорт в .pdf проверить не удалось. Вот такую ошибку выдала программа при экспорте: https://imagizer.imageshack.com/v2/xq90/924/Bk1DIT.png А вот зачем нужно подключать языки (из-за чего программа на каждую страницу тратит чуть ли не по минуте. Вот так было в книге: https://imagizer.imageshack.com/v2/xq90/924/rBGLbH.png Вот так распознала программа: https://imagizer.imageshack.com/v2/xq90/922/Tddze0.png Резюме: на этом уровне OCR-софт работал в "нулевых" годах. Тогда с этим ещё мирились. Сегодня не вижу смысла мучиться с программой, которая не соответствует минимальным требованиям. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}